
Son Previsible benchmark sonuçları, önde gelen yapay zeka modellerinden SEO doğruluğunda şaşırtıcı bir düşüşü ortaya koyuyor.
Özet:
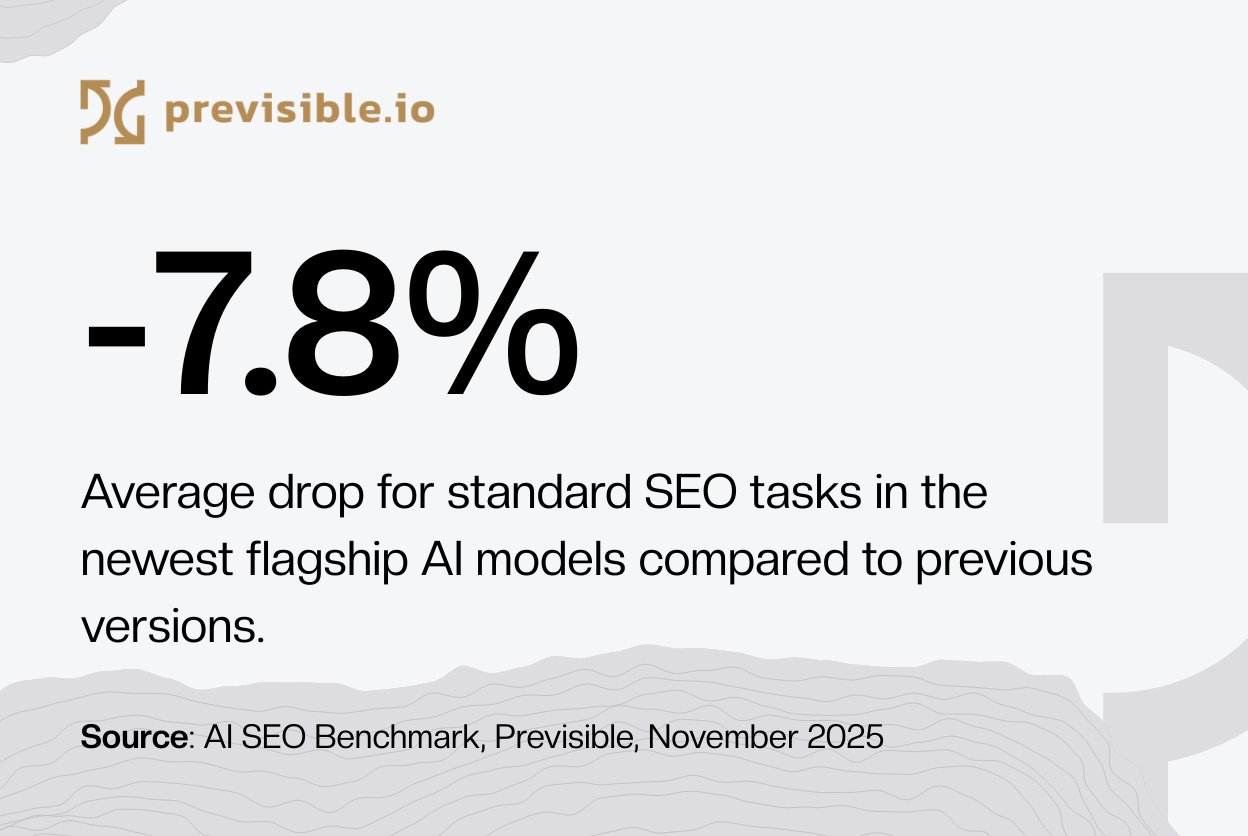
Son bayrak gemisi AI modelleri (Claude Opus 4.5, Gemini 3 Pro), standart SEO görevleri için performansta istatistiksel olarak gerileme gösterdi ve önceki sürümlerle karşılaştırıldığında ~9% doğruluk düşüşü gösterdi.
Bu bir hata değil - şu anda modellerin derin akıl yürütme ve "ajanlık" iş akışları için optimize edildiğinin bir özelliği.
Bu değişime ayak uydurmak için kuruluşların ham ipuçlarına güvenmeyi bırakıp "bağlamsal konteynerlere" geçmeleri gerekir (Özel GPT'ler, Gemler, Projeler).
'Yeni = daha iyi' miti ölmüştür
Geçen sene, hikaye lineerdi: bir sonraki model güncellemesini bekleyin, daha iyi sonuçlar alın. Bu gidişat kırıldı.
AI SEO benchmark'ımızı son model sürümleri - Claude Opus 4.5, Gemini 3 Pro ve ChatGPT-5.1 Thinking - arasında çalıştık ve sonuçlar alarmlı.
Üretken AI çağında, en yeni modeller önceki modellere göre SEO görevlerinde önemli ölçüde daha kötü performans sergiliyor.
Burada bir hata payından bahsetmiyoruz. Neredeyse iki haneli gerilemeler görüyoruz:
| Claude Opus 4.5: 84%'ten (4.1 sürümünden) düşerek %76 aldı. |
| Gemini 3 Pro: Yılın başında test ettiğimiz 2.5 Pro sürümünden devasa %9 düşüşle %73 aldı. |
| Chat GPT-5.1 Thinking: Standart GPT-5'ten %6 düşüşle %77 aldı. Bu, akıl yürütme katmanları eklemenin basit SEO görevleri için gecikmelere ve gürültüye neden olduğunu doğrular. |

Neden önemli: Ekibiniz API çağrılarını veya ipuçlarını "en son model" e güncellediyse, muhtemelen daha kötü sonuçlar için daha fazla ödüyorsunuz.
Tanı: Ajanlık Boşluğu
Neden böyle oluyor? Google ve Anthropic neden "daha aptal" modelleri piyasaya sürsün?
Cevap, onların yeni optimizasyon hedeflerinde yatıyor.
Veri setimize ağırlık verdiğimiz veri kümesindeki başarısızlık noktalarını analiz ettik (test setimizin neredeyse %25'ini oluşturan teknik SEO ve strateji).
Bu yeni modeller, "bir vuruşluk" ipucu için optimize edilmemişlerdir (bir soru sormak ve anında cevap almak).
Bunun yerine,
- Derin akıl yürütme (Sistem 2 düşünme): Basit talimat kümelerini fazla düşünürler, sıklıkla var olmayan karmaşıklığı halüsine ederler.
- Kapsamlı bağlam: Tekil URL parçaları değil, kod tabanlarını veya kitaplıkları beslenmelerini beklerler.
- Güvenlik ve korkuluklar: Teknik bir denetim isteğini reddetmeye daha meyillidirler çünkü bir siber güvenlik saldırısı gibi "görünüyor" veya belirsiz bir güvenlik politikasını ihlal ediyor. Bu reddetme modelini yeni Claude ve Gemini mimarilerinde sıkça gözlemliyoruz.
Ajanlık boşluğundayız. Modeller, konuşmadan önce "düşünmeye" çalışıyorlar.
Ancak, doğrudan, mantıksal SEO görevleri (örneğin bir kanonik etiket analiz etme veya anahtar kelime niyetini haritalama) için bu ekstra "düşünme" gürültüsü doğruluğu zayıflatır.
Düzelme: İpucu Vermeyi Bırakın, Mimari Tasarım Yapmaya Başlayın
Ham ipucu dönemi sona erdi.
Misyon-kritik SEO görevleri için bir temel modeline (kutudan çıkma) güvenemezsiniz.
O 84% doğruluk benchmark'ını geri kazanmak ve aşmak istiyorsanız altyapınızı değiştirmeniz gerekiyor.
- İş akışları için sohbet arayüzünü terk edin
Ekibinizin varsayılan sohbet penceresinde çalışmasına izin vermeyi bırakın.
Ham model, yüksek düzey strateji için gerekli belirli kısıtlamalara sahip değildir.
Dönüşüm: Tekrarlayan tüm görevleri "Bağlamsal Konteynerlere" taşıyın.
Araçlar: OpenAI'nin Özel GPT'leri, Anthropic'in Claude Projeleri ve Google'ın Gemini Gemleri.
- Bağlamı sert kodlayın (RAG lite)
Strateji soruları için puan kaybı, sıkı yönlendirme olmadan yeni modellerin saptığını göstermektedir.
Strateji: Bir modelden "bir strateji oluşturmasını" istemeyin. Ortamı marka yönergeleri, geçmiş performans verileri ve metodolojik kısıtlamalarla yüklemelisiniz.
Neden işe yarar: Bu, modelin akıl yürütme yeteneklerini kendi gerçeğinizde yerleştirmesini, genel tavsiyeleri hayal etmek yerine zorla temellendirmesini sağlar.
- Teknik SEO için modelleri ayarlayın veya "dondurun"
(Durum kodlarını kontrol etme veya şema doğrulaması gibi) ikili görevler için "Düşünme" modelleri gereksiz yere karmaşık ve hata eğilimlidir.
Strateji: Kod tabanlı görevler için eski, kararlı modellere (GPT-4o veya Claude 3.5 Sonnet gibi) yapışın veya belirli teknik denetim kurallarınızı ayarlayacak daha küçük bir modeli özel olarak ayarlayın.
Temel Çıkarımlar
- Yükseltmek için düşürün: Şu anda önceki nesil modeller (Claude 4.1, GPT-5), basit SEO mantık görevlerinde en yeni sürümleri (Opus 4.5, Gemini 3) aşmaktadır. Sürüm numarası daha yüksek diye yükseltmeyin.
- Bir vuruşluk öldü: Tek seferlik ipuçları, yeni "Akıl Yürütme" çağında önemli ölçüde daha sık başarısız olur.
- Her şeyi konteynerleştirin: Tekrarlanabilir bir görevse, Özel GPT, Proje veya Gem'e aittir. Yeni modellerin "akıl yürütme sapması" ile başa çıkmanın tek yolu budur.
- Teknik ve strateji en çok etkilenenlerdir: Verilerimiz bu kategorilerin model gerilemesinden en çok etkilendiğini gösteriyor. Yeni model API'lerinde çalışan herhangi bir otomatik teknik denetimi iki kez kontrol edin.
Stratejik Bakış
Nisan Benchmark'ımızdan bu yana söylüyoruz: Bu modelleri misyon-kritik herhangi bir şey için doğrudan kullanamazsınız.
Ajanlar Çağı'nda İnsan Odaklı SEO
"Sohbet robotları"ndan "ajanlar"a geçiş, SEO yeteneğine ihtiyacı ortadan kaldırmaz, yükseltir.
Bugünün AI modelleri, tak-çalıştır çözümler değildir, becerikli operatörlere ihtiyaç duyan araçlardır.
Tıpkı eğitimsiz tıbbi bir profesyonelden yapay bir ameliyat başarılı şekilde beklemeyeceğiniz gibi, karmaşık bir modele bir ipucu verip yüksek kaliteli SEO sonuçları bekleyemezsiniz.
Başarı, bu yeni çağda modeli tasarlayabilen, iş akışlarına entegre edebilen ve çıktıları düzeltmek, yönlendirmek ve optimize etmek için takdir uygulayabilen insan ekiplerine bağlı olacaktır.
En iyi SEO sonuçları daha iyi ipuçlarından gelmeyecektir.
Bunlar özenle tasarlanmış kısıtlamaları, stratejik bağlamı beslemeyi ve modelleri hassas bir şekilde yönlendirmeyi bilen uygulayıcılardan gelecektir.
Eğer yüksek performanslı bir sistem kurmazsanız, model başarısız olacaktır.



